
Un blog « Jamstack » avec Gatsby JS (feat. GraphQL)

Qu'est ce que la Jamstack ?
JAM pour Javascript, API's, Markup.
Ce terme a été introduit par Mathias Biilmann, fondateur de Netlify (plateforme d’hébergement et de déploiement de sites statiques). Il l’a popularisé dès 2015, puis présenté officiellement lors de la Smashing Conference à San Francisco en 2016.
Par ce terme, Biilman décrit un ensemble de technos qui permettent de créer et propulser des sites dits "statiques". (par site statique, on entend simplement un site dont les pages sont générées lors du build puis servies telles quelles au navigateur de l'utilisateur ).
L'idée derrière cette démarche est de pouvoir s'émanciper des problématiques et la complexité induites par le fonctionnement des sites monolithiques traditionnels...
Le Server Side Rendering
Si je prends le fonctionnement d'un blog Wordpress classique, à chaque fois qu'un utilisateur visite l'une des pages du site :
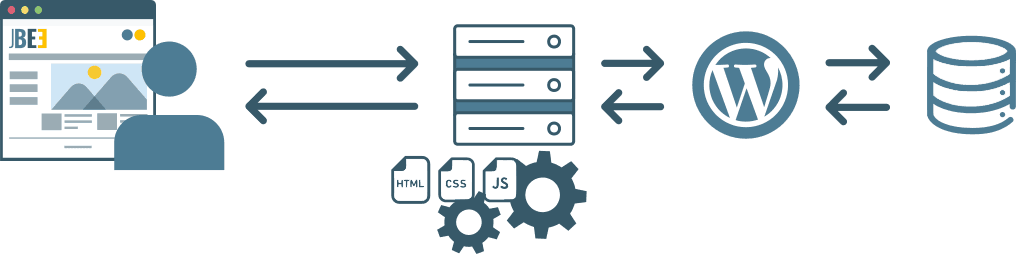
- le navigateur envoie une requête au serveur demandant la page visitée,
- le serveur fait tourner Wordpress pour répondre à la requête
- Wordpress communique avec la base de données pour récupérer / modifier des données et construit la page demandée
- le serveur renvoie la page à l'utilisateur
- On ajoute du cache un peu partout pour essayer d'optimiser le bouzin
Un tel processus présente un certain nombre d'inconvénients :
- la lenteur : toutes les étapes impliquées dans le processus prennent un certain temps.
- la fiabilité : le moindre incident à n'importe quelle étape du processus peut casser le site
- les failles de sécurité potentielles : sécuriser un tel site demande une certaine maintenance (mise à jour des plugins, de wordpress... et chaque mise à jour présente également le risque de casser le site en live... )
La démarche JAMStack
En revanche, dans une démarche JAMStack, le processus à l’œuvre devient beaucoup plus simple :

- le navigateur envoie une requête au serveur demandant la page visitée
- le serveur lui envoie
- Merci bonsoir.
Bien sûr, la Jamstack n’est pas exempte d’inconvénients. Le principal : il faut redéployer le site à chaque modification du contenu. Heureusement, les CMS headless modernes et les pipelines CI/CD rendent ce processus quasi transparent.
Pourquoi choisir la Jamstack en 2025 ?
Presque dix ans après la conférence de Mathias Biilman, les outils à disposition pour élaborer sa Jamstack ont évolué et se sont multipliés. Les metaframeworks tels que Gatsby, Next, Nuxt ou Astro vous permettent de facilement utiliser le mode de rendu SSG (Static Site Generation), les plateformes CDN ou les outils CI/CD vous permettent d'automatiser les déploiements de votre site, les modes de rendus hybrides (avec les server components de React ou l'architecture en îlots façon Astro) ainsi que les fonctions "sans serveur" (serverless functions) vous permettent de rendre une partie de votre site dynamique sans perdre les avantages du rendu SSG....
Bref, en 2025 la Jamstack est toujours clairement d'actualité !
Si bien évidemment, cette stack n'est absolument pas souhaitable pour tous les cas d'usage, dans le cas d'un simple blog, cela semble tout à fait approprié.
Quels outils pour un blog Jamstack ?
Pour faire un blog en suivant les principes de la Jamstack, il va nous falloir au minimum 3 choses :
- Un CMS Headless (Strapi, Contentful ou même Wordpress) pour rédiger le contenu du blog
- Un framework (meta framework) pour générer les pages statiques (Next.js, Nuxt, Astro, Gatsby...)
- Un hébergement pour les pages générées (Vercel et Netlify sont spécialisés dans l'hébergement de site statique, mais n'importe quel hébergement peut faire l'affaire)
Un générateur de pages statiques basé sur React : Gatsby
Pour générer les pages statiques on va porter notre choix sur Gatsby. Ce n'est pas le metaframework qui a le plus de "hype" en ce moment mais il a toujours bonne réputation, est basé sur React et utilise GraphQL. C'est donc également l’occasion de découvrir ce langage de requête d'API ! D'abord, visualisons un peu ce qu'il va se passer :
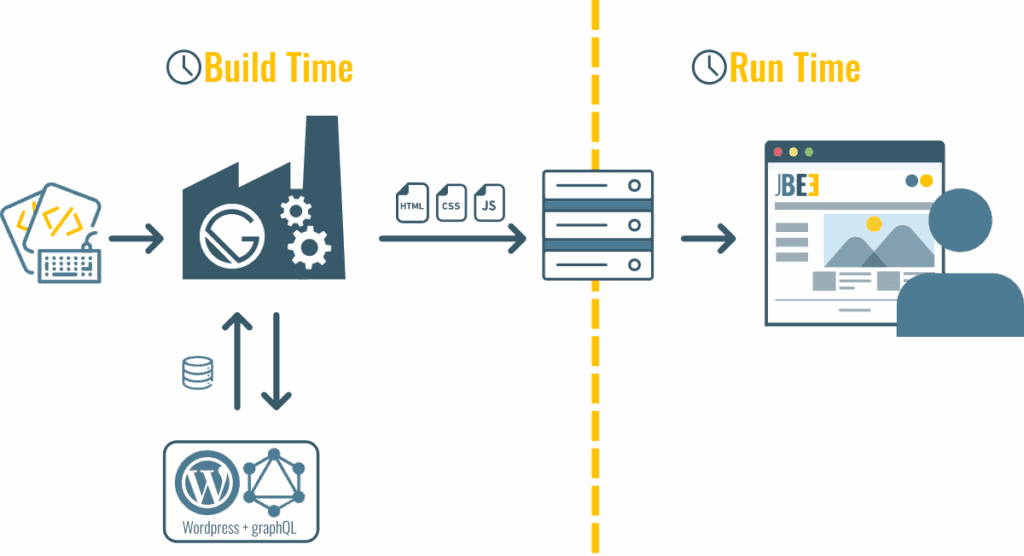
1. On code
2. On lance le build
3. Durant le build, Gatsby va se charger de récupérer les données dont le site a besoin et va générer les pages HTML, avec tout le contenu "statique"
Avec sa très bonne documentation et son excellent CLI, Gastsby s'installe très facilement : vous répondez à quelques questions concernant les features dont vous avez besoin et la CLI vous crée un tout nouveau projet avec le setup qui va bien !
Un coup de gatsby develop, et hop ! Le site est en ligne (http://localhost:8000/) !
Il est donc maintenant temps de rentrer dans le vif du sujet et de commencer à afficher nos articles.
Pour afficher nos articles, l'idée va être de créer dynamiquement une page pour chaque article, et de configurer son URL.
La création dynamique des pages aura lieu dans le fichier gatsby-node.ts.
Le fichier gatsby-node.ts
On va d'abord (comme le propose la documentation Gatsby) créer un fichier gatsby-node.ts à la racine de notre projet.
Le fichier gatsby-node.ts (ou gatsby-node.js si on utilise JavaScript) est un fichier de configuration côté serveur utilisé dans les projets Gatsby. Il permet de personnaliser et d'étendre le processus de construction de Gatsby en utilisant les APIs fournies par Gatsby. Dans ce fichier, nous allons :
- récupérer tous nos articles
- créer une page pour chacun de ces articles
Récupérer tous nos articles avec une première requête GraphQL
Dans cet exemple, nous utilisons (et wp graphQL) Wordpress en mode headess pour nous fournir articles. Bien sûr, en fonction du CMS utilisé, la structure
Dans le fichier gatsby-node, nous allons devoir effectuer notre première requête GraphQL. Pour nous y aider, Gatsby met à notre disposition un outil très pratique : GraphiQL IDE.
Pour accéder à cet outil, il suffit de se rendre sur http://localhost:8000/___graphql lorsque le serveur de développement fonctionne.
Dans notre cas, nous voulons récupérer tous les articles venant d'un back wordpress headless, classés par date ; et pour chaque article nous voulons :
- l'ID
- l'URI
- l'iD de l'article précédent
- l'iD de l'article suivant
Ce qui va nous donner la requête suivante (si nous nommons cette requête "AllPosts") :
JavaScript
query AllPosts {
allWpPost(sort: {date: ASC}) {
edges {
node {
id
uri
}
previous {
id
}
next {
id
}
}
}
}Si on teste cette requête dans GraphiQL, on constate que l'on récupère bien nos articles ! Ça y est nous avons notre requête qui fonctionne ! Mettons la au chaud quelques instants...
⚠️ Gatsby utilise son propre schéma local GraphQL qui n'est pas le même que celui exposé initialement par le CMS.
Créer dynamiquement nos pages pour chacun des articles
Comme nous l'avons dit, le fichier gatsby-node.ts nous permet d'utiliser un certain nombre d'APIs fournies par Gatsby.
Dans notre cas, c'est l'API createPages qui va nous intéresser. Cette API va nous permettre de créer dynamiquement une page pour chaque article que nous recevrons de Wordpress.
Voici une version ultra-simplifiée d'un fichier gatsby-node.ts implémentant l'API createPages avec la requête GraphQL que nous venons de rédiger (basé sur celui du starter fourni en exemple par la documentation Gatsby) :
gatsby-node.ts
TypeScript
import path from "path";
import { slash } from "gatsby-core-utils";
import type { GatsbyNode } from "gatsby";
export const createPages: GatsbyNode["createPages"] = async ({ graphql, actions }) => {
const { createPage } = actions;
const result = await graphql<Queries.AllPostsQuery>(`
query AllPosts {
allWpPost(sort: {date: ASC}) {
edges {
node {
id
uri
}
previous {
id
}
next {
id
}
}
}
}
`);
if (!result || !result.data) {
throw new Error("GraphQL query for posts failed");
}
const allPosts = result.data.allWpPost.edges;
const postTemplate = path.resolve(`./src/templates/post.tsx`);
allPosts.forEach((post) => {
createPage({
path: post.node.uri ?? "",
component: slash(postTemplate),
context: {
id: post.node.id,
previousPostId: post.previous?.id,
nextPostId: post.next?.id,
},
});
});
};Que faisons-nous ici ?
- On exporte une fonction createPages qui va nous permettre d'avoir accès à graphQL et à l'action createPage
- Dans cette fonction, on utilise notre requête GraphQL pour récupérer nos articles
- Une fois les articles reçus, on crée une page en utilisant le composant postTemplate et en lui fournissant le context contenant les IDs de l'article courant, de l'article précédent et de l'article suivant.
Le modèle d'article (post template)
Il nous faut maintenant créer le modèle de page (template) que gatsby-node.ts utilisera pour créer nos pages d'article.
Un modèle de page Gatsby, est un composant React classique à ceci près qu'on peut leur passer un pageContext. (C'est le paramètre context que l'on a donné à la fonction createPage dans le fichier gatsby-node)
On va créer un fichier post.tsx dans le dossier ./src/templates. Ce modèle de page sera utilisé pour créer la page de chaque article.
Une seconde requête graphQL
Dans chaque article on va avoir besoin de données supplémentaires (pour l'instant on n'a que les IDs de l'article courant, de l'article précédent et de l'article suivant).
Pour récupérer ces nouvelles données, on va utiliser une requête de page. L'idée est de récupérer dans chaque page qui sera crée :
- Pour l'article courant
- l'ID
- l'extrait
- le contenu
- le titre
- la date
- les données concernant l'image mise en avant
- Pour l'article précédent et l'article suivant
- le titre
- l'URI
On va donc définir une requête graphQL, qui prendra en paramètres les variables que l'on a définies dans le paramètre context de la fonction createPage dans le fichier gatsby-node.ts. Cela va nous donner quelque chose comme ça :
TypeScript
export const postQuery = graphql`
query PostById($id: String!, $previousPostId: String, $nextPostId: String) {
currentPost: wpPost(id: { eq: $id }) {
id
excerpt
content
title
date(formatString: "MMMM DD, YYYY")
featuredImage {
node {
altText
localFile {
childImageSharp {
gatsbyImageData(width: 1000, quality: 90)
}
}
}
}
}
previousPost: wpPost(id: { eq: $previousPostId }) {
uri
title
}
nextPost: wpPost(id: { eq: $nextPostId }) {
uri
title
}
}
`;Rappel
le résultat de cette requête sera directement disponible dans la prop data de notre composant modèle d'article.
Maintenant on peut créer la fonction qui déclare notre modèle d'article :
TSX
const PostTemplate: React.FC<PageProps<Queries.PostByIdQuery>> = ({
data: { previousPost, nextPost, currentPost },
}) => {
const featuredImage = {
image: currentPost?.featuredImage?.node?.localFile?.childImageSharp?.gatsbyImageData,
alt: currentPost?.featuredImage?.node?.altText || ``,
};
return (
<>
<article className="blog-post" itemScope itemType="http://schema.org/Article">
<header>
<h1 itemProp="headline">{parse(currentPost?.title ?? "")}</h1>
<p>{currentPost?.date}</p>
{featuredImage?.image && <GatsbyImage alt={featuredImage.alt} image={featuredImage.image} />}
</header>
{!!currentPost?.content && <section itemProp="articleBody">{parse(currentPost.content)}</section>}
</article>
<nav className="blog-post-nav">
<ul
style={{
display: `flex`,
flexWrap: `wrap`,
justifyContent: `space-between`,
listStyle: `none`,
padding: 0,
}}
>
<li>
{previousPost && (
<Link to={previousPost.uri ?? ""} rel="prev">
← {parse(previousPost.title ?? "")}
</Link>
)}
</li>
<li>
{nextPost && (
<Link to={nextPost.uri ?? ""} rel="next">
{parse(nextPost.title ?? "")} →
</Link>
)}
</li>
</ul>
</nav>
</>
);
};
Important
Grâce à la fonctionnalité GraphQL TypeGen, il n'est pas nécessaire de créer manuellement l'interface de la réponse graphQL. Si graphqlTypegen est bien à true dans le fichier gatsby-config.js, à chaque fois que gatsby develop sera lancé, Gatsby va créer un type pour chaque requête GraphQL dans le fichier src/gatsby-types.d.ts. On peut ensuite utiliser ce e via l'objet Queries, comme ici :
TypeScript
const PostTemplate: React.FC<PageProps<Queries.PostByIdQuery>> = ({
data: { previousPost, nextPost, currentPost, currentPostHtml },
Voici la version finale de notre fichier post.tsx :
post.tsx
Text
import React from "react";
import { Link, PageProps, graphql } from "gatsby";
import { GatsbyImage } from "gatsby-plugin-image";
import parse from "html-react-parser";
import Layout from "../components/layout";
const PostTemplate: React.FC<PageProps<Queries.PostByIdQuery>> = ({
data: { previousPost, nextPost, currentPost },
}) => {
const featuredImage = {
image: currentPost?.featuredImage?.node?.localFile?.childImageSharp?.gatsbyImageData,
alt: currentPost?.featuredImage?.node?.altText || ``,
};
return (
<>
<article className="blog-post" itemScope itemType="http://schema.org/Article">
<header>
<h1 itemProp="headline">{parse(currentPost?.title ?? "")}</h1>
<p>{currentPost?.date}</p>
{featuredImage?.image && <GatsbyImage alt={featuredImage.alt} image={featuredImage.image} />}
</header>
{!!currentPost?.content && <section itemProp="articleBody">{parse(currentPost.content)}</section>}
<hr />
</article>
<nav className="blog-post-nav">
<ul
style={{
display: `flex`,
flexWrap: `wrap`,
justifyContent: `space-between`,
listStyle: `none`,
padding: 0,
}}
>
<li>
{previousPost && (
<Link to={previousPost.uri ?? ""} rel="prev">
← {parse(previousPost.title ?? "")}
</Link>
)}
</li>
<li>
{nextPost && (
<Link to={nextPost.uri ?? ""} rel="next">
{parse(nextPost.title ?? "")} →
</Link>
)}
</li>
</ul>
</nav>
</>
);
};
export default PostTemplate;
export const postQuery = graphql`
query PostById($id: String!, $previousPostId: String, $nextPostId: String) {
currentPost: wpPost(id: { eq: $id }) {
id
excerpt
content
title
date(formatString: "DD MMMM YYYY")
featuredImage {
node {
altText
localFile {
childImageSharp {
gatsbyImageData(width: 1000, quality: 90)
}
}
}
}
}
previousPost: wpPost(id: { eq: $previousPostId }) {
uri
title
}
nextPost: wpPost(id: { eq: $nextPostId }) {
uri
title
}
}
Une fois nos deux fichiers installés, on doit pouvoir consulter nos articles. Pour cela, on va copier le slug (il est conseillé de configurer les permaliens avec la structure titre de l'article)de notre article à la suite de l'url de notre site :
Text
http://localhost:8000/[slug-de-l-article]/Pour afficher les pages, on peut garder exactement le même logique.
Et si on rajouter un système de commentaire ?
Là nous allons avoir plusieurs problèmes :
- nous n'avons pas forcement de système de commentaires ( certains CMS en intégre nativement mais pas tous) ;
- nous avons un site dynamique mais nous voulons une partie statique ;
- nous voulons également un affichage des commentaire en temps réel (lorsqu'un utilisateur poste un commentaire, ils doit pouvoir le voir immédiatement sans attendre le prochain déploiement !) ;
Pour faire face à tous ces écueils, il existe différentes approches :
Utiliser un service tier pour gérer, héberger et afficher les commentaires
La plus simple est de faire appel à un service tiers hébergera vos commentaires et les afficheront sur votre site via un script embarqué : on copie / colle un script dans notre modèle d'article et un système de commentaire apparaît via une iframe ! On peut difficilement faire plus simple !
Certains de ces services sont des Saas (Disqus), d'autrent peuvent être auto-hébergés (Commento).
😎 Cool !
- Facile à implémenter
- Services déjà intégrés ( BDD, auth, notifications...)
🤨 Pas ouf !
- Dépendance à un service externe
- Pub & tracking pour les solutions propriétaires
Utiliser les système de commentaires du CMS
Certains CMS possèdent nativement leur propre système de commentaires (Wordpress, Drupal). Via leurs API, il est tout à fait possible de poster et de récupérer les commentaires mais cela un certain temps de développement. Il faut également implémenter un moyen mettre à jour votre site (Incremental Static Regeneration, architecture en îlots (Astro) ou les Composants Client de React)
😎 Cool !
- Le système de commentaire n'est pas à code en tant que tel
- Contrôle total de toutes le données de commentaires
🤨 Pas ouf !
- Implémentation nécessaire de l'authentification au CMS
- L'implémentation de la mise à jour de l'interface
Coder soi-même le système de commentaires et utiliser un Backend-as-a-Service (BaaS)
😎 Cool !
- Contrôle total de toutes le données de commentaires
- Services déjà intégrés ( BDD, auth, notifications...)
🤨 Pas ouf !
- Il faut tout coder à la main
- Il faut toujours implémenter de la mise à jour de l'interface
Utiliser Github comme backend pour les commentaires
En voilà une idée qu'elle est bonne ! Giscus et Utterances sont deux scripts qui vont envoyer et récupérer les commentaires de votre site vers un dépôt Git (dans les discussions pour Giscus et dans les issues pour Utterances). Bien sûr, votre dépôt doit être public ! Vous installez l'app de votre choix dans github et après une rapide configuration, vous copiez-collez le script qui vous est donné dans votre modèle d'article et c'est fini.
Vous pouvez admirez le résultat juste en dessous car c'est la solution qui a été choisie pour le présent blog.
😎 Cool !
- Très facile à implémenter
- Services déjà intégrés ( BDD, auth, notifications...)
- Gratuit, sans pub et sans tracking
- Parfait pour un blog de dev dont on imagine aisément que les visiteurs ont déjà un compte github !
🤨 Pas ouf !
- Si vous avec un blog de pâtisserie, il est surement un peudélicat de demander à vos utilisateur d'avoir un compte github....

